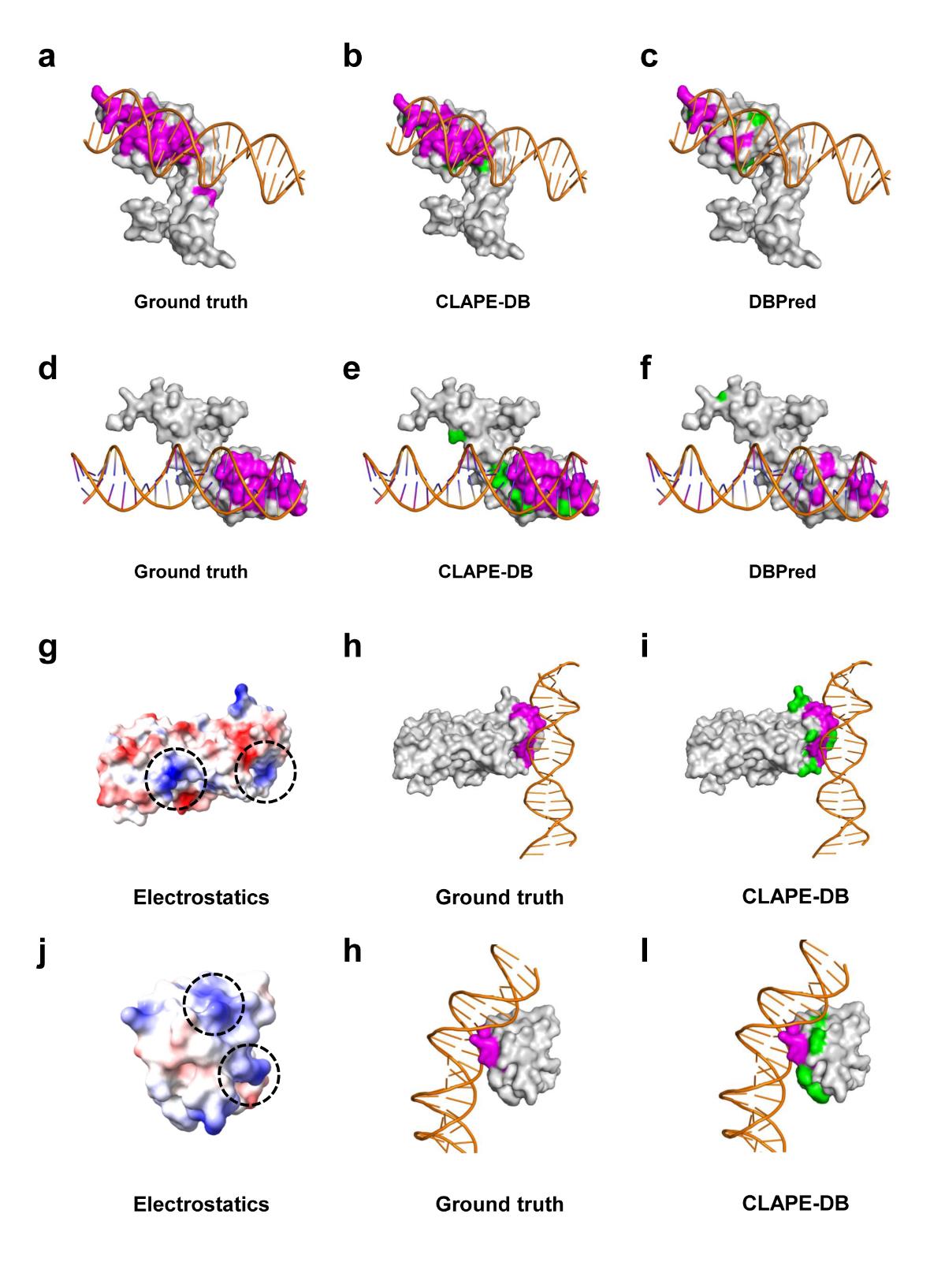
ABSTRACT: Protein-DNA interaction is critical for life activities such as replication, transcription, and splicing. Identifying protein-DNA binding residues is essential for modeling their interaction and downstream studies. However, developing accurate and efficient computational methods for this task remains challenging. Improvements in this area have the potential to drive novel applications in biotechnology and drug design. In this study, we propose a novel approach called CLAPE, which combines a pre-trained protein language model and the contrastive learning method to predict DNA binding residues. We trained the CLAPE-DB model on the protein-DNA binding sites dataset and evaluated the model performance and generalization ability through various experiments. The results showed that the AUC values of the CLAPE-DB model on the two benchmark datasets reached 0.871 and 0.881, respectively, indicating superior performance compared to other existing models. CLAPE-DB showed better generalization ability and was specific to DNA-binding sites. In addition, we trained CLAPE on different protein-ligand binding sites datasets, demonstrating that CLAPE is a general framework for binding sites prediction. To facilitate the scientific community, the benchmark datasets and codes are freely available at this https URL.
文章链接:https://academic.oup.com/bib/article/25/1/bbad488/7505238